Leading Inference Providers Cut AI Costs by up to 10x With Open Source Models on NVIDIA Blackwell
Source: NVIDIA AI Blog
Why Token Cost Matters
AI‑powered interactions—from diagnostic insights in healthcare to character dialogue in games and autonomous customer‑service agents—are built on the same unit of intelligence: a token.
Scaling AI interactions forces businesses to ask: Can we afford more tokens?
The answer lies in better tokenomics—the practice of reducing the cost of each token.
Recent MIT research shows that advances in infrastructure and algorithms are cutting inference costs for frontier‑level performance by up to 10× annually.
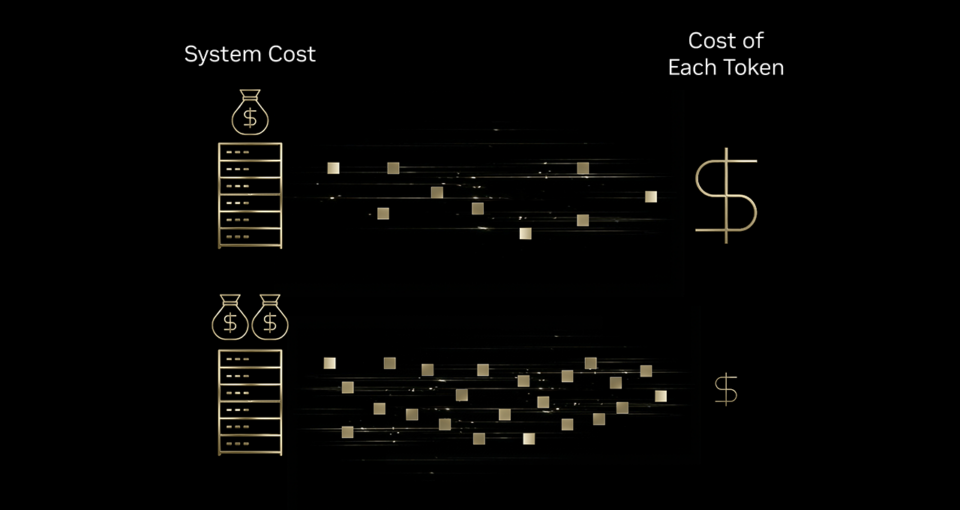
Infrastructure Efficiency = Better Tokenomics
Think of a high‑speed printing press:
- If the press can produce 10× more pages with only a modest increase in ink, energy, and machine cost, the cost per page drops dramatically.
Similarly, investments in AI infrastructure boost token output far more than they raise total cost, leading to a meaningful reduction in cost per token.
Who’s Leading the Charge?
Leading inference providers are already leveraging the NVIDIA Blackwell platform to slash token costs:
- Baseten
- DeepInfra
- Fireworks AI
- Together AI
These providers:
- Host advanced open‑source models that have reached frontier‑level intelligence.
- Combine open‑source intelligence with the extreme hardware‑software codesign of NVIDIA Blackwell.
- Deploy their own optimized inference stacks.
The result? Up to 10× lower cost per token compared with the previous NVIDIA Hopper platform, unlocking dramatic savings for businesses across every industry.
Takeaway
Improving tokenomics isn’t just a technical tweak—it’s a strategic lever that lets companies scale AI interactions affordably. By adopting cutting‑edge infrastructure like NVIDIA Blackwell, organizations can deliver richer, more frequent AI experiences while keeping costs in check.
Healthcare – Baseten and Sully.ai
Cutting AI Inference Costs by 10×
In healthcare, tedious, time‑consuming tasks such as medical coding, documentation, and insurance‑form management eat into the time physicians can spend with patients.
Sully.ai tackles this problem by creating “AI employees” that automate routine tasks like medical coding and note‑taking. As the platform grew, its proprietary, closed‑source models introduced three major bottlenecks:
| Bottleneck | Impact |
|---|---|
| Unpredictable latency | Slowed real‑time clinical workflows |
| Rising inference costs | Costs grew faster than revenue |
| Limited model control | Inability to fine‑tune quality or updates |
Solution
Sully.ai switched to Baseten’s Model API, which deploys open‑source models (e.g., gpt‑oss‑120b) on NVIDIA Blackwell GPUs. The stack includes:
- NVFP4 low‑precision data format for efficient inference
- NVIDIA TensorRT‑LLM library for optimized execution
- NVIDIA Dynamo inference framework for streamlined deployment
Baseten selected Blackwell GPUs after observing up to 2.5× better throughput per dollar compared with the previous Hopper‑based setup.
Results
| Metric | Improvement |
|---|---|
| Inference cost | ↓ 90 % (≈ 10× reduction) |
| Response time | ↑ 65 % faster for critical workflows (e.g., medical‑note generation) |
| Physician time saved | > 30 million minutes returned |
Links
- Sully.ai website
- Baseten case study: 30 M clinical minutes saved
- NVFP4 data format announcement
- NVIDIA Dynamo inference framework
Gaming — DeepInfra and Latitude Reduce Cost per Token by 4×
Latitude is building the future of AI‑native gaming with its AI Dungeon adventure‑story game and the upcoming AI‑powered role‑playing platform Voyage, where players can create or explore worlds with the freedom to choose any action and craft their own story.
The Challenge
- Each player action triggers an inference request to a large language model (LLM).
- Costs grow with engagement, yet response times must stay fast enough to keep the experience seamless.
The Solution
Latitude runs large open‑source models on DeepInfra’s inference platform, which is powered by NVIDIA Blackwell GPUs and TensorRT‑LLM.
For a large‑scale mixture‑of‑experts (MoE) model, DeepInfra reduced the cost per million tokens:
| Platform | Cost / 1 M tokens |
|---|---|
| NVIDIA Hopper (baseline) | $0.20 |
| Blackwell (FP16) | $0.10 |
| Blackwell (NVFP4, low‑precision) | $0.05 |
Result: a 4× reduction in cost per token while preserving the accuracy expected by customers.
Benefits for Latitude
- Fast, reliable responses even during traffic spikes.
- Ability to deploy more capable models without compromising player experience.
- Cost‑effective scaling as player engagement grows.

Latitude’s text‑based adventure “AI Dungeon” generates narrative text and imagery in real time as players explore dynamic stories.
Agentic Chat — Fireworks AI and Sentient Foundation Lower AI Costs by up to 50 %
Sentient Labs brings AI developers together to build powerful, open‑source reasoning AI systems. Their mission is to accelerate AI progress on harder reasoning problems through research in:
- Secure autonomy
- Agentic architecture
- Continual learning
Sentient Chat
Sentient Chat is the first application from Sentient Labs. It:
- Orchestrates complex multi‑agent workflows
- Integrates more than a dozen specialized AI agents contributed by the community
Because a single user query can trigger a cascade of autonomous interactions, the service has massive compute demands and can generate costly infrastructure overhead.
How the Cost Savings Were Achieved
Sentient Labs moved to Fireworks AI’s inference platform running on NVIDIA Blackwell GPUs. The Blackwell‑optimized inference stack delivered 25‑50 % better cost efficiency compared with the previous Hopper‑based deployment.
Key outcomes
- Higher throughput per GPU → more concurrent users for the same cost
- Scalable platform supported a viral launch of 1.8 M wait‑listed users in 24 hours
- Processed 5.6 M queries in a single week while maintaining low latency
“With Fireworks’ Blackwell‑optimized inference stack, Sentient achieved 25‑50 % better cost efficiency compared with its previous Hopper‑based deployment.” – Sentient Labs
Visual Overview
Learn More
- Read the full story on Fireworks AI.
Customer Service — Together AI and Decagon Drive Down Cost by 6×
Customer‑service calls that use voice AI often end in frustration: even a slight delay can cause users to talk over the agent, hang up, or lose trust.
Decagon builds AI agents for enterprise customer support, and voice is its most demanding channel. The company needed infrastructure that could deliver sub‑second responses under unpredictable traffic loads while keeping token‑economics viable for 24/7 voice deployments.
Solution
Together AI runs production inference for Decagon’s multimodel voice stack on NVIDIA Blackwell GPUs. The two companies collaborated on several key optimizations:
| Optimization | Description |
|---|---|
| Speculative decoding | Smaller “draft” models generate fast responses; a larger model verifies accuracy in the background. |
| Conversation caching | Frequently repeated dialogue elements are cached to accelerate response generation. |
| Automatic scaling | Dynamic scaling handles traffic surges without degrading performance. |
Results
- Response time: dramatically reduced, enabling seamless voice interactions.
- Cost per token: up to 6× lower than previous Hopper‑based deployments.
NVIDIA’s extreme codesign across every layer of the stack—spanning compute, networking, and software—and its partner ecosystem are unlocking massive reductions in cost per token at scale. This momentum continues with the NVIDIA Rubin platform, which integrates six new chips into a single AI supercomputer to deliver 10× performance and 10× lower token cost over Blackwell.
Learn More
Explore NVIDIA’s full‑stack inference platform to see how it delivers better tokenomics for AI inference: