I stopped storing chats and built a stateful study agent instead !!
Source: Dev.to
What this is
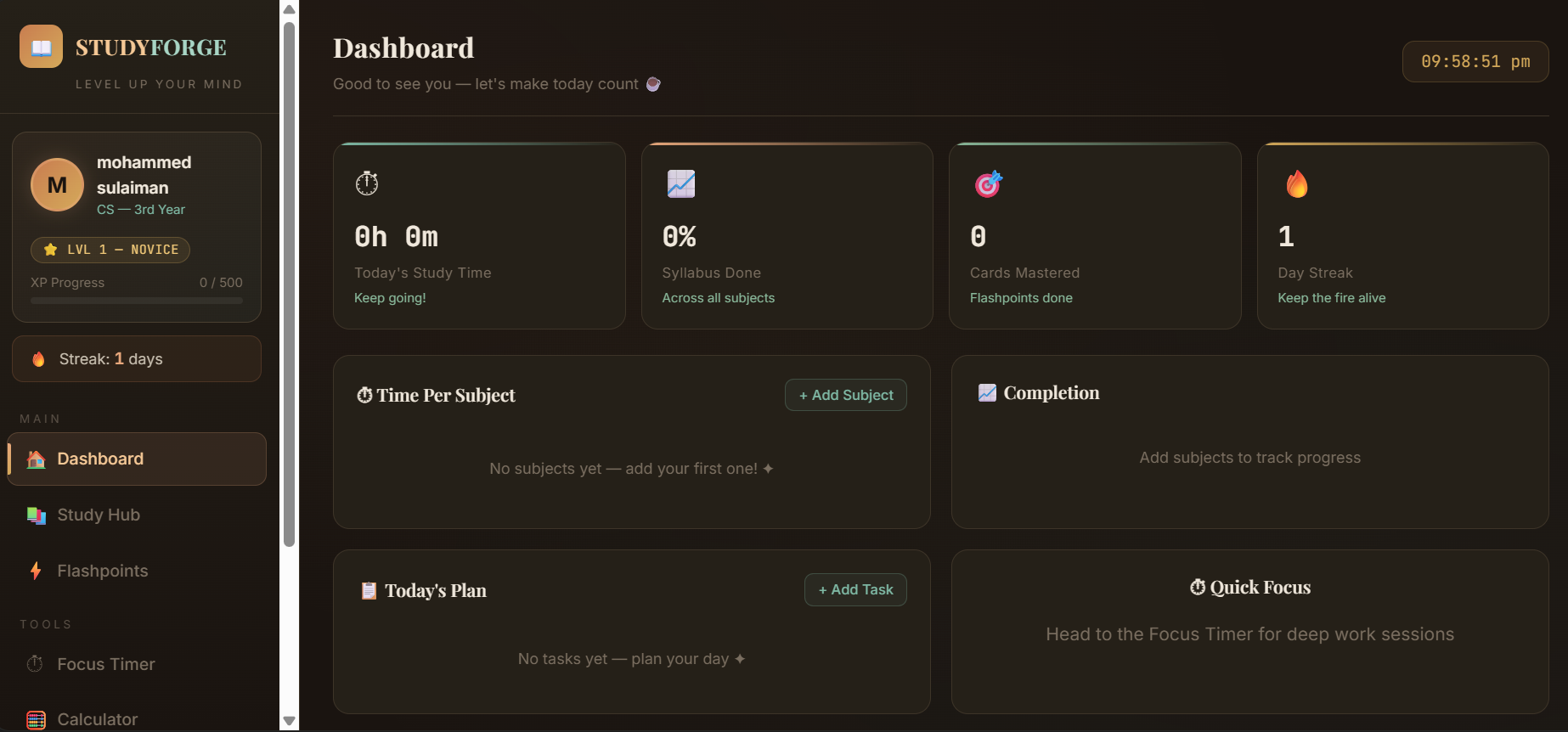
My team and I built a single‑page app that combines a few things students usually use separately:
- A Pomodoro timer with session tracking
- Flashcards with feedback loops
- A quiz system that logs mistakes
- A simple chatbot
- Progress tracking like XP, streaks, and subjects
Everything runs in the browser. No backend. Data is stored locally.
The interesting part isn’t the features — it’s how they all feed into a shared memory layer.
The problem: fake memory
The first version of the chatbot didn’t actually remember anything.
You could tell it you’re weak at something, and in the very next message it would ignore that completely.
It wasn’t because the model was bad. It was because every interaction was stateless—each message was treated like a fresh start.
What I tried first
We started with the obvious approach: pass previous messages back into the system.
That helped a little, but it created new problems:
- Context quickly filled with irrelevant messages
- Old conversations polluted new responses
- Prompts grew without improving quality
- There was still no real understanding of the user
It felt like I was simulating memory instead of actually building it.
The shift: stop storing chats
The turning point was simple:
I stopped storing conversations.
Instead, I stored state—very small, structured pieces of information such as:
- Weak topics
- Current tasks
- Active subjects
- Study activity
No chat logs. No transcripts. Just signals.
This approach is similar to how systems like Hindsight treat memory—focusing on structured recall instead of replaying conversations. Their documentation and ideas around agent memory helped reinforce that this direction made sense.
Where the data comes from
The key idea was to stop asking the user directly. Instead, I inferred everything from behavior:
- If a user gets a quiz question wrong, that topic becomes a weakness.
- If they mark a flashcard as “Again”, that’s another signal.
- Completing a study session updates activity.
Over time, the system builds a picture of the user without requiring explicit input. This turned out to be much more reliable.
How responses changed
Instead of feeding in past conversations, I started passing a small, structured summary of the user’s state, e.g.:
- What they struggle with
- What they’re currently working on
- What they’ve been studying recently
That context is small but highly relevant, and it made a big difference.
Before vs. after
Same question: “What should I study today?”
- Before: A generic answer with no personalization.
- After: A specific suggestion based on weak topics and current tasks.
Nothing about the model changed—only the input context changed.
Persistence
Everything is stored locally in the browser. When the page reloads, the state is restored.
I deliberately avoided adding a backend because for this kind of system:
- The data is user‑specific
- Simplicity matters more than scale
- Fast iteration matters more than infrastructure
Local storage was enough.
What didn’t work
A few things I tried and dropped:
- Storing full chat conversations
- Trying to summarize chats
- Adding more and more context
None of these improved behavior in a meaningful way; they mostly added noise.
Where this still breaks
The system works, but it’s not perfect:
- Weak topics never decay over time
- All signals are treated equally
- There’s no sense of time or recency
- Everything is stored globally instead of per subject
Its simplicity shows these limitations.
What I’d change next
If I continue this, I’d focus on:
- Weighting topics based on frequency
- Reducing the importance of older data
- Separating memory by subject
- Possibly adding sync across devices
But I’d keep the same core idea.
Takeaway
The system didn’t improve when I added more memory.
It improved when I became selective about what to remember.
Chat history felt like memory. Structured state actually worked.
Curious how others are approaching this.
Are you storing more data, or just better data?