GPU autoscaling on Kubernetes with KEDA: Building an external scaler
Source: CNCF Blog
The problem
KEDA is built with CGO_ENABLED=0. The NVIDIA Management Library (NVML)—the standard way to read GPU metrics—requires CGO, so you can’t just add a GPU scaler to KEDA core the way you’d add a Prometheus or Kafka scaler.
A second issue is that KEDA’s operator runs as a single deployment. NVML calls are local—they read metrics from the GPU on the same node. You can’t query GPU 0 on node‑A from a pod running on node‑B.
Thus a native KEDA scaler was off the table. We needed something that runs on every GPU node and exposes metrics over the network.
The architecture
To solve this, we can build a custom DaemonSet (see the reference implementation: keda-gpu-scaler) that runs on GPU nodes. In this architecture, each pod:
- Calls NVML via
go-nvmlto read local GPU metrics. - Serves them over gRPC using KEDA’s
ExternalScalerinterface. - The KEDA operator connects to the scaler and drives HPA decisions.
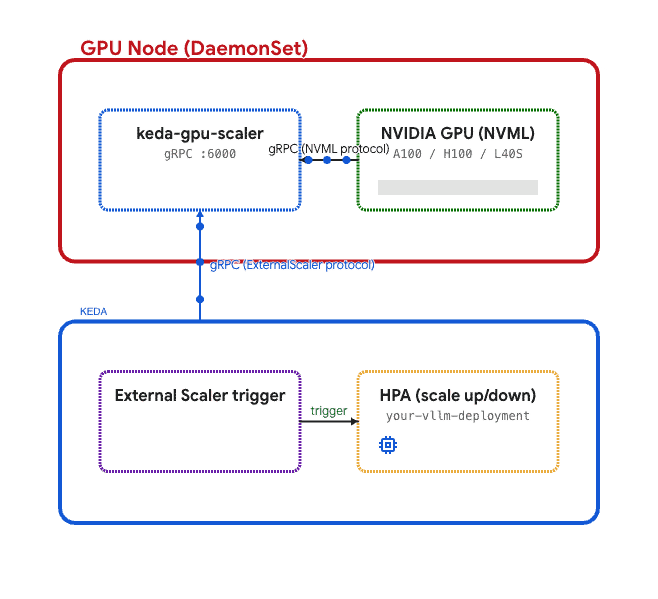
This follows the same pattern Kubernetes uses for device plugins and the metrics server—a per‑node agent that collects local hardware data.
What you can scale on
The scaler exposes these metrics per GPU:
| Metric | Description |
|---|---|
gpu_utilization | SM (compute) utilization percentage |
memory_utilization | Memory controller utilization |
memory_used_percent | VRAM usage as a percentage |
temperature | GPU die temperature in Celsius |
power_draw | Current power consumption in watts |
For multi‑GPU nodes you can choose an aggregation method: max, min, avg, or sum. You can also target a specific GPU index.
Pre‑built profiles
Most users run one of a few common GPU workload types, so the scaler includes ready‑made profiles with sensible defaults:
triggers:
- type: external
metadata:
scalerAddress: "keda-gpu-scaler.gpu-scaler.svc.cluster.local:6000"
profile: "vllm-inference"| Profile | Metric | Target | Activation | Use Case |
|---|---|---|---|---|
vllm-inference | memory_used_percent | 80% | 5% | LLM serving, scale‑to‑zero |
triton-inference | gpu_utilization | 75% | 10% | Triton model serving |
training | gpu_utilization | 90% | 0% | Training jobs, no scale‑to‑zero |
batch | memory_used_percent | 70% | 1% | Batch inference, aggressive scale‑down |
You can override any value, or skip profiles entirely and set metricType, targetValue, and activationThreshold directly.
Quick start
Install with Helm
helm install gpu-scaler deploy/helm/keda-gpu-scaler \
--namespace gpu-scaler --create-namespaceThe chart deploys a DaemonSet that targets nodes with nvidia.com/gpu.present=true and tolerates the nvidia.com/gpu taint. It uses the NVIDIA container runtime by default—if your cluster doesn’t have that, set nvmlHostMounts.enabled=true to mount the device files directly.
Create a ScaledObject
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: vllm-gpu-scaler
spec:
scaleTargetRef:
name: vllm-deployment
minReplicaCount: 0
maxReplicaCount: 8
triggers:
- type: external
metadata:
scalerAddress: "keda-gpu-scaler.gpu-scaler.svc.cluster.local:6000"
profile: "vllm-inference"That’s it. KEDA will now scale your vLLM deployment based on GPU memory usage, including scale‑to‑zero when idle.
Testing without GPUs
The scaler includes a mock collector mode for testing. The e2e test suite spins up a real gRPC server with fake GPU data and exercises the full IsActive → GetMetricSpec → GetMetrics flow (11 tests covering profiles, error paths, streaming, aggregation modes). All tests run in CI without any GPU hardware.
go test -v -tags=e2e -race ./tests/e2e/What’s next
Building custom external scalers is a powerful way to extend the CNCF ecosystem. It shows how a graduated project like KEDA can remain flexible, allowing engineers to build custom DaemonSets that fit newer AI infrastructure patterns without forcing every workload into the same abstraction.
The code snippets and repository shared above serve as an open‑source reference implementation of this architecture. If you’re running GPU workloads on Kubernetes and want autoscaling that natively understands GPU metrics, exploring KEDA’s ExternalScaler interface is a fantastic place to start.
GitHub: keda-gpu-scaler