Google's new Gemma 4 12B model is designed to run on any laptop with 16GB of RAM
Source: Ars Technica
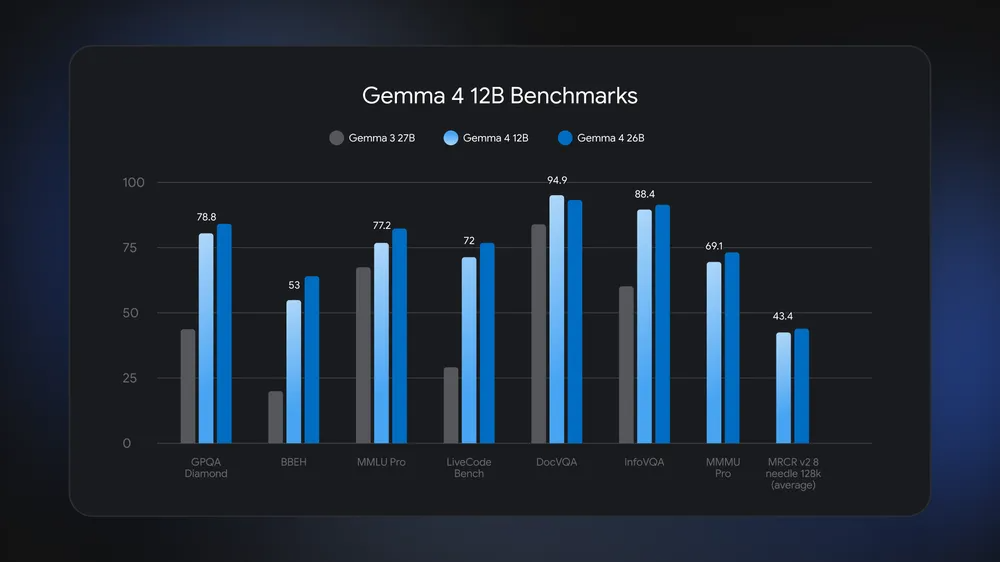
Model Overview
Google says the new Gemma 4 12B model is capable of complex multistep reasoning and agentic workflows that previously required the larger Gemma variants. Despite having only 12 billion parameters, it approaches the capability of the 26 billion‑parameter version.
Multi‑Token Prediction (MTP)
Gemma 4 12B includes the newly devised Multi‑Token Prediction (MTP) drafters, which exploit unused processing cycles to calculate possible future tokens. This yields greater speed and efficiency. While optional MTP versions exist for the other Gemma 4 models, the 12B variant ships with MTP enabled out of the box.
Multimodal Efficiency
The Gemma 4 family is natively multimodal, accepting text, audio, or images as inputs. Most generative AI models use dedicated encoders for non‑text inputs, adding latency and memory overhead.
Gemma 4 12B streamlines this with:
- Vision – a single‑matrix‑multiplication embedding module with positional embeddings, allowing image data to be passed directly to the LLM with spatial awareness, eliminating a bulky middle‑encoder.
- Audio – no separate encoder; raw audio signals are projected into the same vector space used for text tokens.
Availability
You can try Gemma 4 12B without downloading via tools such as:
The model weights (≈ 18 GB) are available for local download on:
With 16 GB of RAM, the model can run on a typical laptop.