Evicting MCP tool calls from your Kubernetes cluster
Source: Dev.to
Overview
Model Context Protocol (MCP) has been wobbling on its own legs for a while now, which articulated a frustration many of us in the agentic space have felt but hadn’t quantified:
LLMs are exceptional code generators, but terrible state machines.
The industry standard for agents is the ReAct pattern (Reason + Act), which essentially turns your LLM into a pseudo‑runtime. The model decides on a tool, calls the API, waits for the network response, parses the JSON result, and repeats. This approach isn’t efficient with today’s LLMs: you’re asking a probabilistic engine to handle deterministic control flow, leading to hallucinations, rapid context‑window pollution, and fragile state management.
I have tried to implement the Code Mode pattern for Kubernetes diagnostics. Instead of exposing atomic tools (list, get, log, etc.) for the LLM to orchestrate sequentially, a sandbox with a runtime was exposed. The LLM writes a program, and the agent executes it. The results aren’t just “better”; they represent a fundamental shift in how agents should interact with infrastructure.
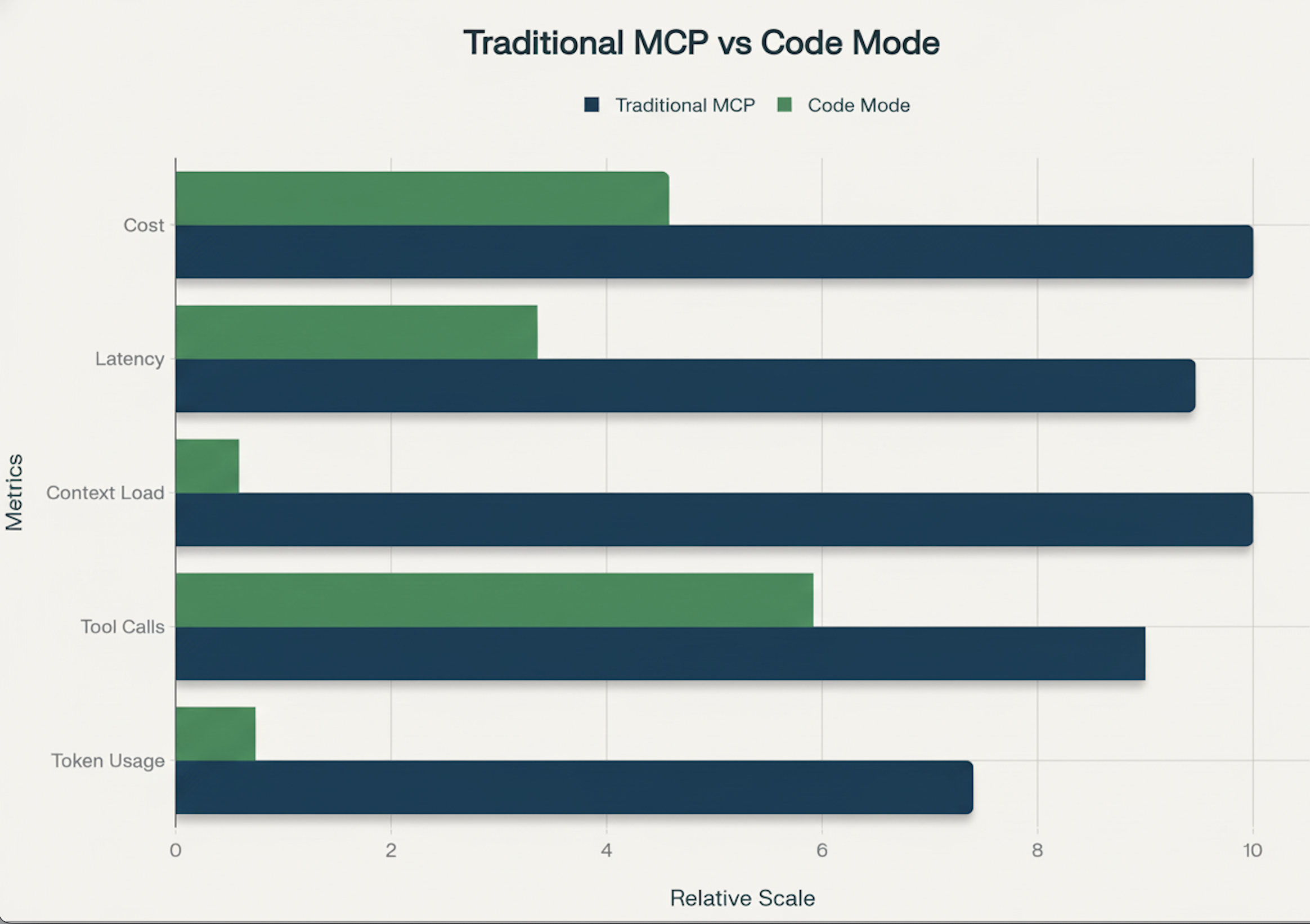
In real debugging sessions, traditional task workflows (pinpointing the issue for a failed pod from the logs) can climb to around 1 million tokens over 8–10 tool calls. The same investigations in Code Mode land in the 100–200 k token range—a ~2–10× reduction, with context‑heavy tasks sometimes saving more than 90 % of tokens.
The Economics of Context
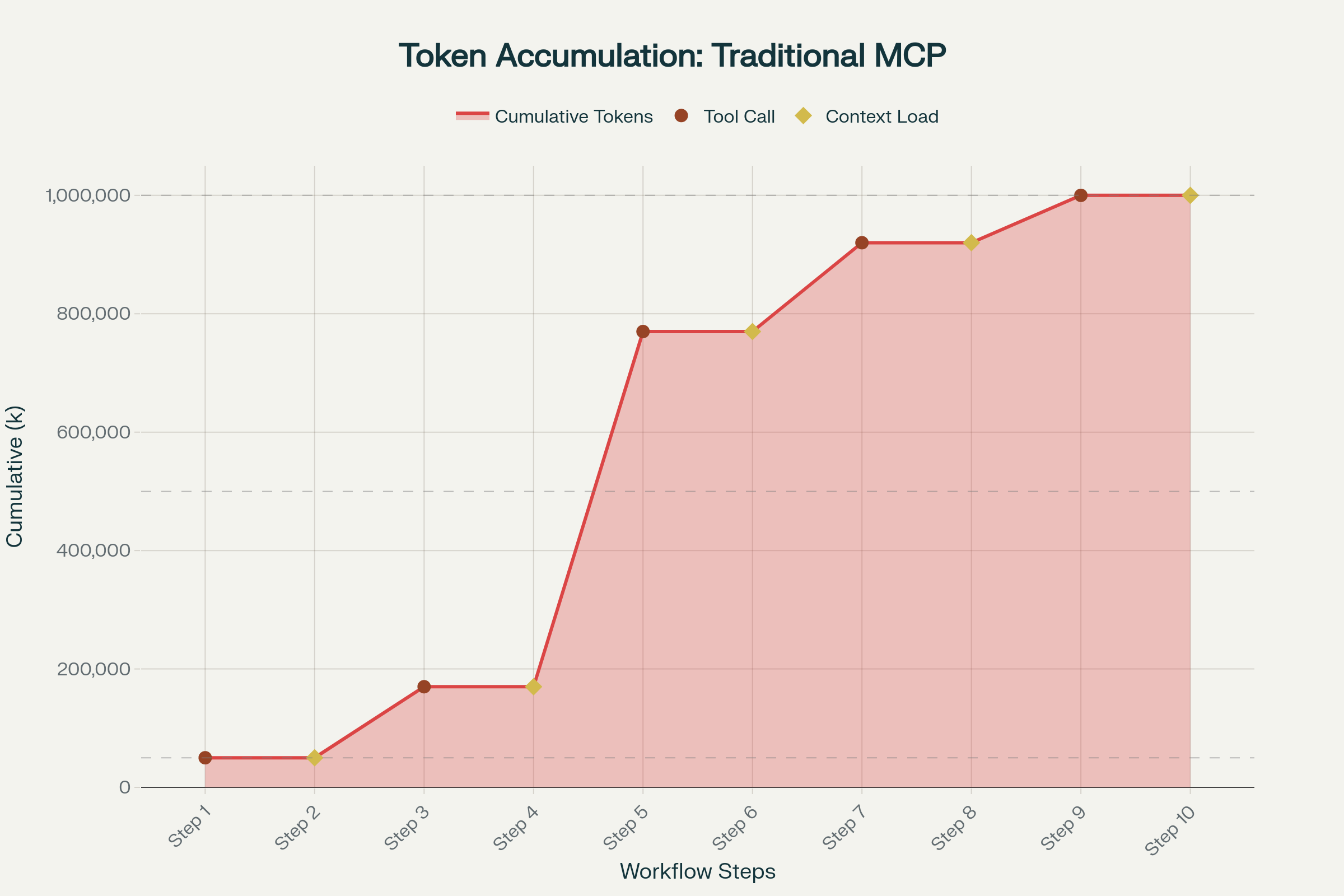
In production Kubernetes workflows (where logs are large), a standard “tell me why the pod is broken” workflow typically consumes 1 M+ tokens over 8–10 turns. Each tool call adds intermediate JSON to the context, increasing the surface area for hallucination.
Traditional MCP tool‑call chains are also not efficient for prompt caching because each interaction fundamentally changes the conversation context (Claude prompt caching docs).
By switching to Code Mode, the model receives a prompt, writes a single code block, and receives the final distilled answer. This eliminates unnecessary tool calls, drastically cutting token usage, latency, and hallucination rate. Recent benchmarks by Anthropic showed a workflow drop from 150 k tokens to ~2 k tokens (up to 98 % context saving). In our own Kubernetes scenarios we’ve seen similar reductions (up to 90 %).
- Traditional Tool‑Use: ~1 M tokens / 8‑10+ round‑trips.
- Code Mode: ~100‑200 k tokens / 4‑6+ round‑trips.
Why It Works
Code Mode aligns the architecture with the training data. Frontier LLMs are heavily pre‑trained on valid, executable code and understand control flow, error handling, and data filtering implicitly.
Conversely, the interactive tool‑calling paradigm forces LLMs to:
- Manage loop state across stateless HTTP requests.
- Parse verbose JSON while ignoring noise from previous calls.
Moving execution logic into a deterministic sandbox offloads the strict logic—looping, filtering, conditional waiting—to a runtime designed for it. The LLM essentially writes a script such as:
“Loop through all pods; if a pod restarts > 5 times, fetch its logs, grep for ‘Error’, and return the result.”
The sandbox executes this loop in milliseconds. The LLM never sees the raw list of 500 healthy pods; it only sees the final root cause. Intermediate results are processed in the sandbox rather than polluting the context window, which Anthropic notes as a common cause of degraded agent performance.
According to Anthropic’s internal testing, Code Mode also significantly improves accuracy. This aligns with broader research showing that LLMs struggle when forced to return code wrapped in JSON: Aider’s benchmarks found lower‑quality code when models must ensure JSON format validity while solving the coding problem.
High‑Order Kubernetes Diagnostics
This shift enables workflows that were previously cost‑prohibitive or technically impossible due to context limits.
1. “Cluster health scan” scenario
Old Way: The agent lists all pods, then describes each via multiple tool calls, quickly hitting rate or context limits.
New Way: The agent writes a loop.
// Execution inside the sandbox
const pods = tools.kubernetes.list({ namespace: 'default' });
const problems = pods
.filter(p => p.status === 'CrashLoopBackOff')
.map(p => {
const logs = tools.kubernetes.logs({ name: p.metadata.name });
return analyze(logs);
});
return problems;The entire scan happens off the main LLM chat chain.
2. Configuration Drift & Audits
An agent can pull a Helm release manifest (tools.helm.get) and the live Kubernetes object (tools.kubernetes.get), diff them in‑memory within the sandbox, and return only the drift. Doing this via standard tool calling would require pasting two massive YAML files into the context window.
3. Event‑Driven Debugging
Because the sandbox provides a true runtime, the agent can write polling logic. It can check a deployment status, wait 5 seconds, and check again without burning a single token on the “wait” state. This enables atomic “Rollout and Verify” operations that feel like magic compared to the stuttering steps of a chat‑based agent.
4. PII Data Fetching
Code Mode with MCP provides a critical security advantage for Kubernetes environments: sensitive data never touches the LLM’s context window. In traditional tool‑calling, when an agent retrieves API credentials, database passwords, or service‑account tokens from Kubernetes Secrets, those values flow into the cloud model provider’s network. With Code Mode, the sandbox handles the secrets internally, and only the sanitized result is returned to the LLM.