Engineering Platform Trust: Cutting Customer Case Volume 20x with Petabyte-Scale Health Signals
Source: Salesforce Engineering
By Sanjeevani Bhardwaj, Ganesh Prasad, Sukumar Surya, and Thomas Bohn.
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today we spotlight Sanjeevani Bhardwaj, CSG Product Director, who leads the Technical Health Score to make platform trust measurable by scoring Salesforce implementations through analytics pipelines that process petabytes of telemetry and historical context.
Explore how the team engineered a system that converts platform trust into actionable signals by defining technical health consistently across multi‑tenant environments and building scalable machine‑learning pipelines that deliver proactive health insights.
What is your team’s mission in building the Technical Health Score within Customer Success Core?
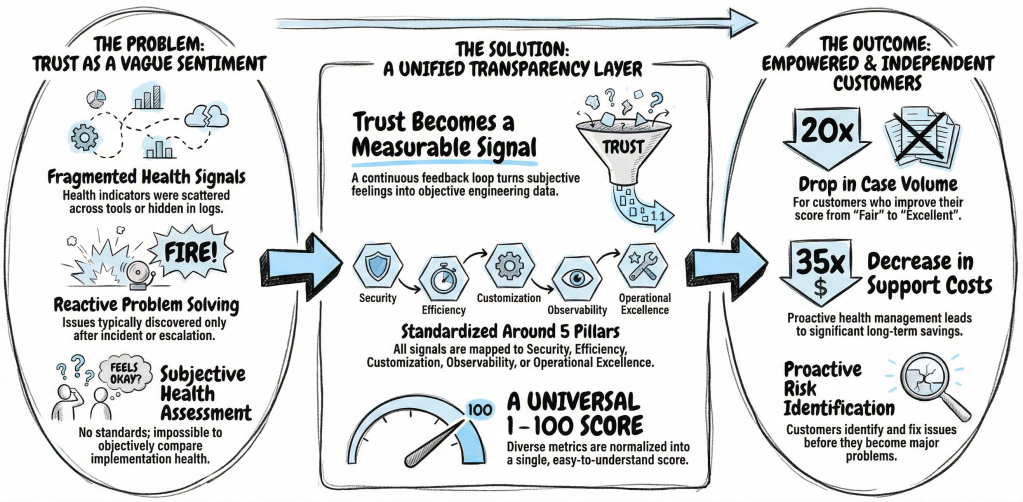
The team builds a transparency layer for the Salesforce platform to turn trust from a subjective sentiment into a measurable engineering signal. Understanding implementation health becomes difficult as you adopt more products and deepen your customizations. Technical Health provides an objective view of that status and offers a clear path toward improvement.
- Trust erodes when health indicators stay fragmented across tools or hidden in logs until incidents occur.
- To solve this, the team designed a continuous feedback loop that aggregates signals across efficiency, security, operational excellence, customization, and observability.
- This structure allows you to identify risks and optimize your implementation before issues surface as escalations.
The ultimate goal centers on your independence. Maintaining a healthy Salesforce implementation requires continuous effort as your organization evolves, and this score guides that effort over time. By standardizing technical health through a consistent interface, the team helps you balance innovation with stability throughout the lifecycle of your Salesforce footprint.
What definition and standardization constraints shaped how the team defined “technical health” for Salesforce customers?
Inconsistency creates a major hurdle for Salesforce users. Customers span various industries and architectural patterns, yet everyone needs a shared definition of health. Without a standard framework, technical status remains subjective and impossible to compare across different organizations.
The team introduced a five‑pillar taxonomy to serve as a universal interface for technical health:
- Security
- Efficiency
- Operational Excellence
- Customization
- Observability
Every signal maps into one of these pillars. This structure allows the system to evaluate health consistently regardless of which clouds or features you use. The abstraction helps the score scale across an evolving platform while maintaining its core meaning.
Standardization also requires a common health currency. The team normalized diverse metrics into a unified 1 – 100 scale, which lets you view health holistically instead of interpreting disconnected indicators. Distribution‑based normalization ensures the system evaluates you against peers with similar scale and complexity. This approach creates a definition of technical health that stays both precise and fair.
What data‑scale constraints shaped how the team curated technical health signals from petabytes of Salesforce telemetry?
Extracting meaningful health signals from a massive telemetry surface presents a significant data challenge. These signals originate from UI interactions, API traffic, and security configurations spread across various databases and logs. Many of these sources only retain raw data for short periods.
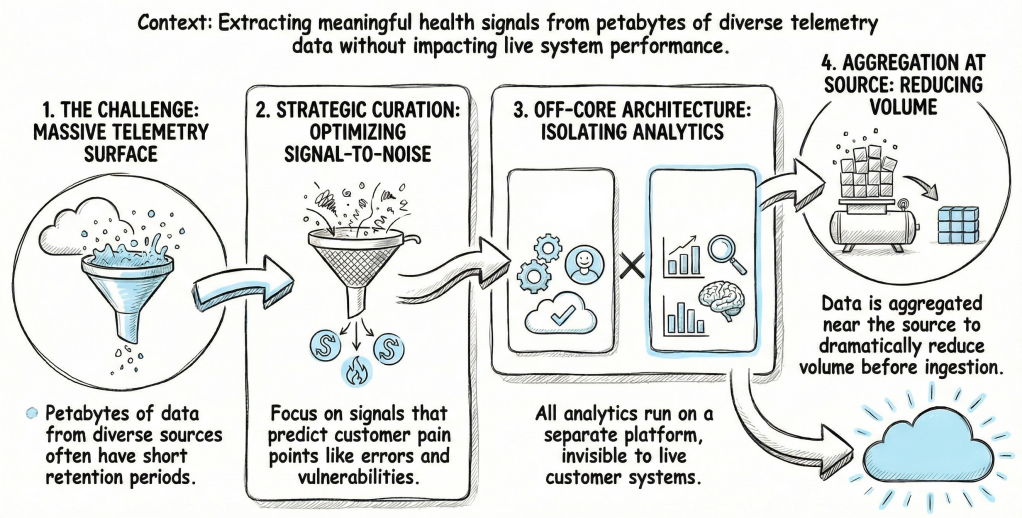
The team designed the system around strategic curation instead of ingesting every data point. They identified signals that predict unhealthy behavior by focusing on common pain points like limits, errors, and security vulnerabilities. This method improves the signal‑to‑noise ratio and keeps the system manageable at scale.
- All analytics run on an off‑core data platform, isolated from live transactional systems to prevent any impact on daily operations.
- Aggregation occurs near the source to reduce data volume before ingestion.
- This approach allows the platform to process massive amounts of telemetry with historical context while remaining invisible to your workloads.
What correctness and explainability constraints shaped how the Technical Health Score distinguishes customer misconfiguration from platform issues?
Maintaining trust requires a clear distinction between platform behavior and user configuration. Performance issues often stem from both sources, but conflating them undermines the credibility of any health metric.
The team engineered a signal‑qualification framework based on shared responsibility. Every signal must pass an actionability gate: if you cannot fix the issue through code or configuration changes, the system excludes that signal from your score. This ensures your Technical Health Score reflects your specific implementation choices rather than platform incidents.

Transparency drives the model… (content continues)
Engineering Process
While complex neural networks offer theoretical accuracy, they often fail to explain why a score changed. The team built a multi‑stage machine learning pipeline to prioritize explainability:
- Signal normalization – All signals are mapped onto a common 0–100 scale using statistical distributions.
- Partial Least Squares regression – Weights these signals against historical outcomes.
- Simple weighted averages – Aggregate the final data.
This design provides a complete audit trail. You can drill down from a top‑level score to individual root causes without any ambiguity.
What outcome‑validation constraints shaped how the team proved the Technical Health Score drives measurable results?
Validating impact requires operationalizing the score within existing workflows. The team embedded Technical Health into customer‑success processes to trigger proactive engagement. This shift moves the focus from reactive support to preventive action.
Back‑testing results
- Users with low scores experience more high‑severity incidents and higher costs.
- Users who improve their score from Fair to Excellent see case volumes drop by nearly 20×.
- Support costs for these users also decrease by ≈ 35×.
Benefits
- Internal teams reduce data‑gathering cycles from weeks to hours.
- Users gain access to 12 months of curated health history.
- Proactive refactoring before peak seasons flattens support demand.
These outcomes prove that Technical Health serves as a lever for reliability, providing a clear path toward sustained success on the platform.
Learn More
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.