Designing GenAI Systems with Cost–Latency–Quality Trade-offs
Source: Dev.to
Source: Dev.to
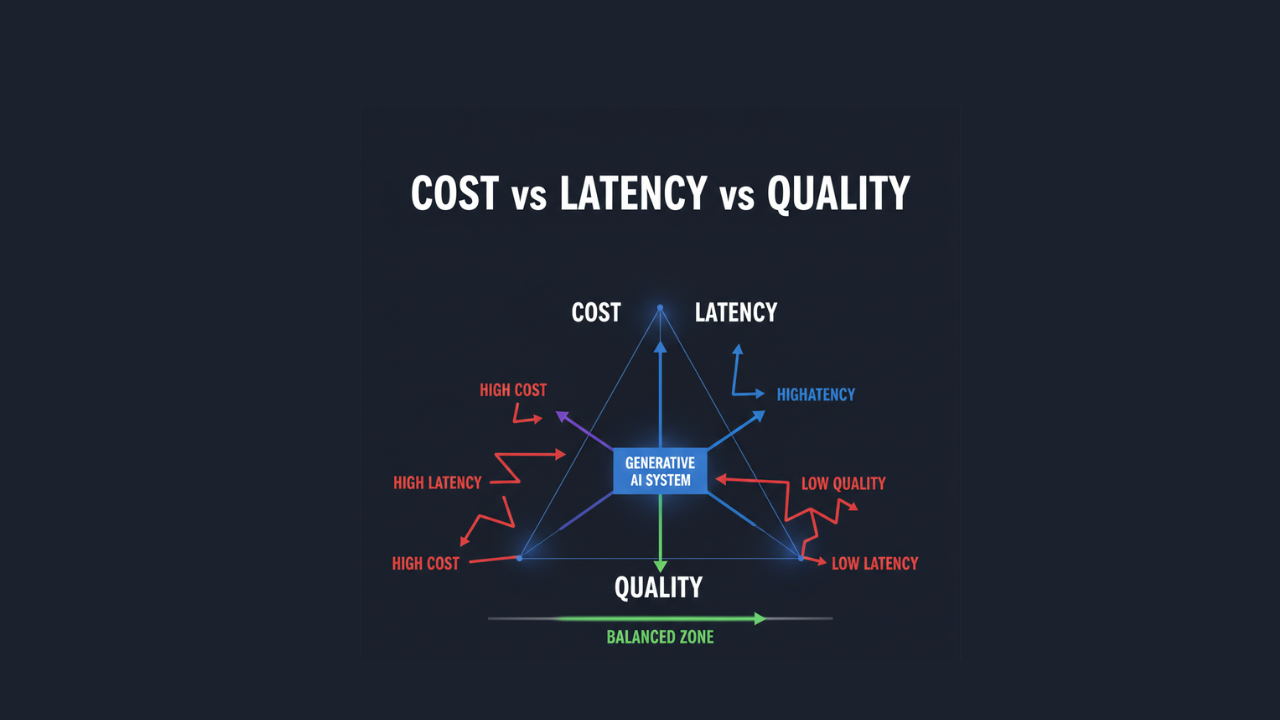
[](https://dev.to/shreekansha97)The Tri‑Factor Constraint
In modern system design, Generative AI introduces a unique “Tri‑Factor Constraint.”
Unlike traditional distributed systems—where the trade‑off is often between consistency, availability, and partition tolerance (CAP)—GenAI systems operate within a triangle of Cost, Latency, and Quality.
| Factor | Description |
|---|---|
| Cost | Computational expenditure per request, typically measured in tokens or FLOPs. |
| Latency | Time‑to‑first‑token (TTFT) and total generation time. |
| Quality | Semantic accuracy, reasoning depth, and adherence to constraints. |
- Cost – The computational expenditure per request, typically measured in tokens or FLOPs.
- Latency – The time‑to‑first‑token (TTFT) and total generation time.
- Quality – The semantic accuracy, reasoning depth, and adherence to constraints.
Optimizing for one factor almost invariably degrades the others:
- A high‑reasoning model (Quality) requires massive parameter counts, leading to higher inference costs and slower processing (Latency).
- Aggressive quantization or smaller models (Latency/Cost) frequently result in hallucinations or a lack of nuanced understanding (Quality).
Architectural Levers
1. Context‑Window Lever
- What it does: Extending the context length gives the model more “in‑context” examples or retrieved data (RAG).
- Benefit: Improves generation quality and factuality.
- Cost: Memory and compute grow linearly (or quadratically for some attention implementations), and the time‑to‑first‑token (TTFT) rises because the KV‑cache must be pre‑filled.
2. Quantization Lever
- What it does: Convert weights from FP16 → INT8 → INT4 (or other low‑bit formats).
- Benefit: Reduces memory‑bandwidth and storage requirements, yielding higher throughput and lower inference cost.
- Trade‑off: Introduces a perplexity gap – a modest drop in predictive accuracy that can affect generation quality if the quantization is too aggressive.
3. Inference‑Engine Lever
- Technique: Speculative Decoding – a small “draft” model proposes tokens that a larger “verifier” model validates.
- Benefit: Cuts latency dramatically while preserving the quality of the larger model’s outputs.
- Complexity: Adds orchestration overhead and requires careful scheduling of compute resources to keep both models efficiently utilized.
Tiered Intelligence and Dynamic Routing
A mature GenAI architecture does not treat every query as equal. A simple greeting should not be routed to the same computational resource as a complex, multi‑step logical proof.
flowchart TD
A[Incoming Request] --> B[Semantic Router / Classifier]
subgraph Tier1[Tier 1: Low Latency / Cost]
B --> C1[(7B‑parameter model<br/>Greetings, Formatting, Extraction)]
end
subgraph Tier2[Tier 2: Balanced]
B --> C2[(70B‑parameter model<br/>Summarization, Content Generation)]
end
subgraph Tier3[Tier 3: High Reasoning]
B --> C3[(Expert Ensemble<br/>Coding, Logic, Sensitive Analysis)]
end- By implementing a semantic router, the system can:
- Deliver high average quality.
- Keep blended cost and latency significantly lower than a monolithic‑model approach.
Implementation: Dynamic Routing Logic
The following Python example illustrates a basic routing mechanism that selects a model based on an estimated “complexity score” derived from the user’s input.
import time
import asyncio
from typing import Dict
class ModelRegistry:
"""Holds the configuration for each model tier."""
def __init__(self) -> None:
self.tiers: Dict[str, Dict[str, object]] = {
"lightweight": {"endpoint": "model-7b-v1", "cost_per_1k": 0.0001},
"standard": {"endpoint": "model-70b-v1", "cost_per_1k": 0.002},
"premium": {"endpoint": "model-expert-v1", "cost_per_1k": 0.01},
}
class AIRouter:
"""Selects the appropriate model tier for a given prompt."""
def __init__(self, registry: ModelRegistry) -> None:
self.registry = registry
def classify_complexity(self, prompt: str) -> str:
"""
In production this would use a lightweight classifier or a
heuristic‑based analysis of the input string.
For this demo we simply use word count as a proxy.
"""
word_count = len(prompt.split())
if word_count < 10:
return "lightweight"
elif word_count < 30:
return "standard"
else:
return "premium"
async def route(self, user_prompt: str) -> Dict[str, object]:
"""
Determines the tier, calls the appropriate inference endpoint,
and returns basic metrics (latency & cost estimate).
"""
tier_key = self.classify_complexity(user_prompt)
config = self.registry.tiers[tier_key]
start = time.perf_counter()
# -----------------------------------------------------------------
# Replace the line below with the real async inference call, e.g.:
# response = await call_inference(config["endpoint"], user_prompt)
# -----------------------------------------------------------------
await asyncio.sleep(0) # placeholder for async call
latency = time.perf_counter() - start
return {
"tier": tier_key,
"endpoint": config["endpoint"],
"latency": latency,
"cost_est": config["cost_per_1k"], # Simplified cost calculation
}ModelRegistry– Stores endpoint URLs and per‑1k‑token cost for each tier.AIRouter.classify_complexity– A placeholder heuristic that maps prompt length to a tier.AIRouter.route– Performs the routing, measures latency, and returns a small summary.
Replace the placeholder await asyncio.sleep(0) with your actual asynchronous inference call (e.g., await call_inference(...)). This cleaned‑up version is ready to be copied into documentation or a notebook.
Multi‑tenant Cost‑Quality Differentiation
In SaaS environments, tiered intelligence is not just a performance optimization; it’s also a business model. Architects can map different intelligence tiers to user subscription levels.
- Free tier – mandatory routing to lightweight models with aggressive context truncation.
- Enterprise tier – access to high‑reasoning models with dedicated throughput (Provisioned Concurrency) to ensure stable latency under load.
Monitoring and Feedback Loops
To manage these trade‑offs, systems require a “Semantic Observability” stack.
- Model‑as‑a‑Judge – Use a high‑quality model to periodically audit the outputs of lightweight models and detect quality drift.
- Latency‑Bucketed Evals – Measure how quality degrades as you enforce stricter latency timeouts.
- Cost Attribution – Tag each request with its tier and compute cost to enable granular billing and capacity planning.
Granular Tracking
- Track which features or users are consuming the most expensive computational tokens.
Real Production Examples
Customer Support Bots – Cascading Architecture
- A 7B model attempts to answer from a cached FAQ.
- If the confidence score is low, the request escalates to a 70B model.
- If that still fails, the transcript is summarized for a human agent.
Search Engines – Dual‑Pass Processing
- A fast, low‑latency model generates an initial summary for immediate display.
- Simultaneously, a more thorough verification model runs in the background; if it detects errors, the UI is updated with the corrected result.
Engineering Anti‑patterns
The “Smartest Model” Fallacy – Defaulting to the most capable model for every task leads to unsustainable burn rates and sluggish user experiences.
Ignoring Pre‑fill Latency – Failing to account for the time it takes to process long system prompts. A 2,000‑token system prompt can add hundreds of milliseconds to the time‑to‑first‑token (TTFT) regardless of generation speed.
Implicit Retries – Automatically retrying failed requests on the same high‑latency model. Falling back to a “safe” or “faster” model is often the better UX.
System Design Reasoning
The goal of a senior architect is not to build the “best” AI system, but the most “appropriate” one for the use case.
- Real‑time code autocomplete – Latency is the primary constraint; a 100 ms delay is a failure.
- Legal discovery tool – Quality is the primary constraint; a 1‑minute delay is acceptable if accuracy is near‑perfect.
Architectural Takeaway
Modern GenAI design is moving away from model‑centric thinking toward pipeline‑centric thinking. The model is merely one component in a broader system of routers, caches, verifiers, and retrievers. Success is defined by the ability to dynamically shift the system’s position within the Cost–Latency–Quality triangle based on real‑time constraints and user intent.