Designing a Crash-Safe, Idempotent EVM Indexer in Rust
Source: Dev.to
Building a Data Pipeline That Survives Failures Without Corrupting State
Data pipelines don’t fail because they’re slow.
They fail because they write partial state, retry blindly, and restart into inconsistency.
When building an EVM indexer, the real challenge isn’t fetching blocks — it’s answering a harder question:
If the process crashes halfway through indexing a block, what state does the database end up in?
If the answer is “it depends,” the system isn’t safe.
This article walks through how I designed a Rust‑based EVM indexer that:
- Processes blocks atomically
- Is safe to retry
- Never commits partial state
- Recovers deterministically after crashes
- Avoids duplicate data without sacrificing correctness
Stack
- Rust (Tokio)
ethers-rsfor RPC- PostgreSQL
- SQLx
- Axum for query API
The Real Problem: Partial State
Let’s say block N contains:
- 120 transactions
- 350 logs
Naïvely, you might:
- Insert block
- Insert transactions
- Insert logs
- Update checkpoint
But what if the process crashes after inserting transactions but before inserting logs?
Now your database contains:
- Block exists
- Transactions exist
- Logs missing
- Checkpoint not updated
On restart you must decide:
- Do you retry?
- Do you skip?
- Do you overwrite?
- Do you detect partial writes?
Most indexers get this wrong.
Design Goals
Before writing code, I defined strict invariants:
- A block is either fully written or not written at all.
- Restarting must be safe.
- Duplicate processing must not corrupt state.
- Checkpoint must reflect durable state.
- No external consistency assumptions.
The design centers on one idea: The database is the source of truth. The process is disposable.
System Architecture
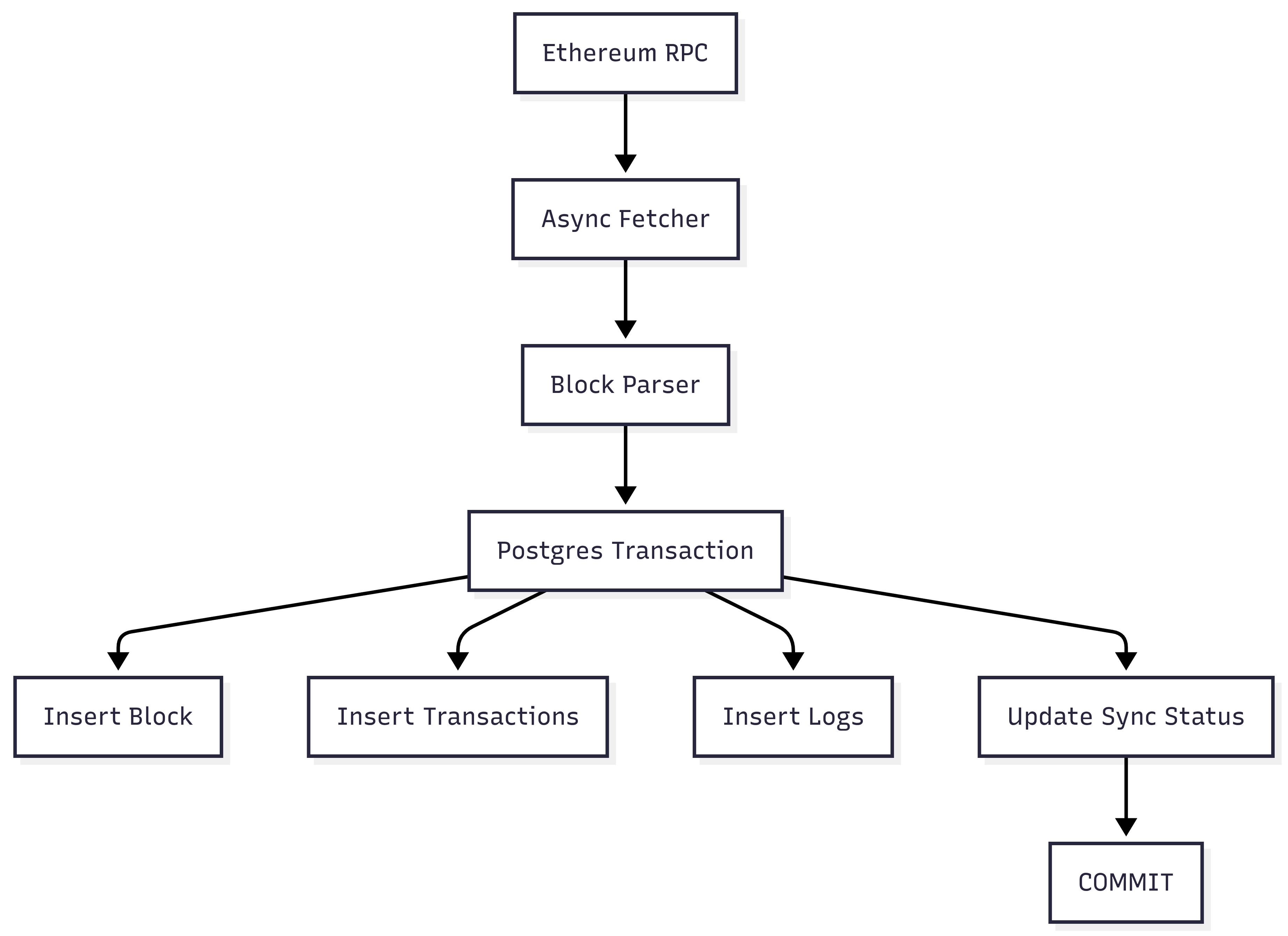
Everything for a single block happens inside one PostgreSQL transaction.
Either everything commits or nothing exists—no partial state.
Atomic Block Processing
The core pattern looks like:
let mut tx = pool.begin().await?;
store_block(&mut tx, &block).await?;
store_transactions(&mut tx, &block).await?;
store_logs(&mut tx, &block).await?;
update_checkpoint(&mut tx, block_number).await?;
tx.commit().await?;Key detail: The checkpoint update is inside the same transaction.
If the transaction rolls back:
- The block isn’t stored.
- The checkpoint doesn’t move.
Recovery becomes trivial.
What Broke First
Originally, I updated the checkpoint after committing block data. It worked—until I simulated crashes.
If the process crashed:
- Block was stored.
- Checkpoint wasn’t updated.
On restart the system re‑processed the same block, causing:
- Duplicate insert attempts.
- Foreign‑key constraint violations.
- Messy recovery logic.
Fix: Move the checkpoint update inside the block transaction.
Now:
- Commit guarantees durable block + checkpoint.
- Rollback guarantees nothing happened.
- Restart logic becomes deterministic.
Lesson: Recovery logic must be part of the write path, not an afterthought.
Idempotency Strategy
Crashes, retries, and RPC timeouts happen. The system must be safe to retry the same block multiple times. All inserts use:
INSERT ... ON CONFLICT DO NOTHINGWhy?
- If the block already exists, ignore.
- If a transaction already exists, ignore.
- If a log already exists, ignore.
Calling sync_block(N) ten times produces the same state as calling it once.
Idempotency is not an optimization—it is survival.
Isolation Level Considerations
PostgreSQL defaults to READ COMMITTED. For this indexer that’s sufficient because:
- Blocks are processed sequentially.
- No concurrent writers modify the same block.
If I parallelized block ingestion, I would evaluate:
REPEATABLE READfor consistency, or- Explicit row‑level locking, or
- Partitioned writes.
Atomicity matters more than raw speed.
Failure Scenarios Modeled
The system was built assuming failure is normal. Handled scenarios:
| Scenario | Outcome |
|---|---|
| Crash before commit | Entire transaction rolls back; checkpoint unchanged. |
| Crash after commit | Checkpoint updated; block fully durable. |
| Duplicate processing | Safe due to ON CONFLICT DO NOTHING. |
| RPC timeout | Retry with exponential backoff; idempotent writes keep it safe. |
| Database lock contention | Transaction scope kept minimal; no external I/O inside the transaction. |
Design principle: Every block sync must be atomic and idempotent.
Runtime Observations
During sustained historical sync:
- Average block processing time: ~5–15 ms (RPC‑bound)
- Database time per block: Throughput
Strict per‑block transactions add minor overhead.
Trade‑off:
- Slightly higher write latency
- Massive increase in correctness guarantees
In indexing systems, corrupted data is worse than delayed data.
What I Would Improve Next
- Parallel historical sync with a bounded worker pool
- Reorg‑safe rollback logic
- Partitioned block tables
- WAL‑based replication for read scaling
- Prometheus metrics for ingestion lag
Lessons Learned
The hardest part of backend systems is not performance—it’s state recovery.
Making writes atomic simplified:
-
Retry logic
-
Crash recovery
-
Reasoning about invariants
-
Rust helped enforce correctness.
-
PostgreSQL enforced durability.
-
Transactions enforced sanity.
The system is not optimized for speed; it is optimized for being correct when things go wrong.
That is what matters in infrastructure.