Delivering Accurate, Low-Latency Voice-to-Form AI in Real-World Field Conditions
Source: Salesforce Engineering
Engineering Energizers Q&A: Voice‑to‑Form Data Capture
In our Engineering Energizers Q&A series, we highlight the engineering minds driving innovation across Salesforce. Today, we feature Rajashree Pimpalkhare, SVP of Software Engineering, Field Service, and the team responsible for voice‑to‑form data capture in the Field Service Mobile application, which delivers AI‑powered mobile experiences to a field workforce supporting hundreds of thousands of active technicians each month.
Discover how her team:
- Developed a hybrid on‑device and cloud architecture to accurately translate unstructured voice input into structured form data at an enterprise scale.
- Ensured reliable performance across various accents and noisy field conditions through real‑world voice testing.
- Managed latency, cost, and privacy by keeping speech‑to‑text on the device while leveraging cloud LLMs for intelligent field mapping.
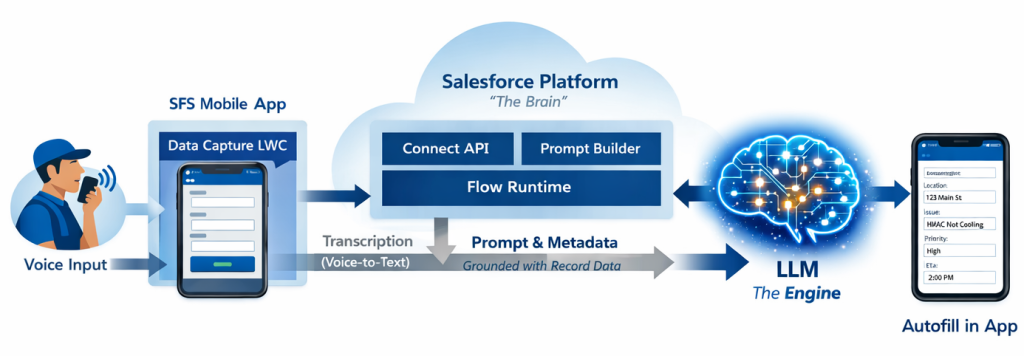
AI‑driven data flow process diagram.
What is your team’s mission as it relates to building voice‑to‑form data capture for the Field Service Mobile application?
Our mission focuses on streamlining field work. We empower technicians to capture data quickly, safely, and accurately using natural voice interactions. Field technicians often work in environments where traditional data entry is difficult—such as when wearing gloves, handling equipment, or in dangerous locations. This makes voice a more effective way to input information.
From an engineering standpoint, our mission goes beyond simple speech recognition; it involves intelligent data capture. Technicians provide a natural summary of their work, and the system directly maps that input to structured form fields. Form structures, field semantics, and technician language differ significantly across customers and industries. Therefore, this mapping requires semantic understanding, not just deterministic parsing. Without AI‑based semantic reasoning, this method would depend on rigid, form‑specific rules, which would not scale across various industries or schemas.
Voice‑to‑form is a core feature within Field Service Mobile. It integrates directly into existing record editing and form workflows, allowing for gradual adoption without introducing new interaction models or requiring user retraining. The outcome is a production‑grade experience that enhances efficiency while meeting enterprise demands for accuracy, reliability, and trust.
What accuracy constraints did you encounter when mapping unstructured voice input into structured form fields at enterprise scale?
The central accuracy challenge involved converting free‑form speech into correctly populated, structured fields. This task spanned diverse industries, form designs, and technician speaking styles. Technicians commonly use domain‑specific terminology, abbreviations, and relative date references. The system must interpret these accurately within each field’s data type and format.
As the number of form schemas increases, deterministic approaches would demand per‑form logic to manage overlapping field names, varying data types, and context‑dependent references. This quickly leads to a combinatorial maintenance issue. To resolve this, the team developed a hybrid architecture that combines on‑device speech‑to‑text with cloud‑based large language models for semantic field mapping. Each request incorporates schema‑driven metadata—field types, constraints, examples, and formatting expectations—encoded directly into the prompt alongside the user’s utterance, avoiding reliance on post‑processing heuristics.
AI proved to be the only practical method to generalize intent resolution across hundreds of form variations without hard‑coding logic. The team validated accuracy through iterative testing across various device classes, form sizes, and real‑world noise conditions, utilizing a growing collection of authentic technician utterances. Evaluation focused on correct field assignment and valid value population, achieving 85 % field‑level accuracy, which serves as a robust production baseline.
What reliability constraints emerged when supporting diverse voices, accents, and noisy field environments across real technician workflows?
Reliability challenges arose from the varied conditions in real‑world field environments, including differences in accents, speech cadence, vocabulary, and background noise from traffic or machinery. Such conditions can create inconsistency if not specifically addressed in both architecture and testing.
The team established reliability engineering in real‑world conditions by creating a Voice Utterance Library. This library contains authentic technician voice clips captured during field ride‑alongs. They systematically combined these utterances with various noise profiles and replayed them through the entire pipeline. Failures were categorized based on whether errors originated in transcription, semantic interpretation, or field assignment, allowing for targeted refinement and making AI behavior observable rather than opaque.
On‑device transcription, utilizing native iOS and Android speech frameworks, provides consistent performance in mobile environments. When transcription quality fluctuates, technicians can review and edit the text before processing, preventing low‑confidence inputs from propagating into structured records. This layered strategy ensures reliable performance across diverse field conditions.
What latency constraints shaped how you balanced on‑device speech‑to‑text with server‑side text‑to‑form processing for voice workflows?
Latency directly affects usability in the field. Technicians expect quick feedback, even when network conditions vary. The team needed to minimize perceived delay while still using cloud intelligence for semantic understanding.
The architecture separates transcription from semantic processing. Speech‑to‑text operates entirely on th
Device‑side processing
This removes network dependency and provides predictable performance. Only the resulting text and metadata transmit to the server for field mapping, reducing payload size and avoiding audio transmission. This separation ensures AI inference applies only where semantic reasoning is necessary.
The system completes a single server round‑trip for text‑to‑form processing, avoiding compounding delays. A review step lets technicians edit transcriptions before submission, adding a quality gate without stopping progress. Together, these choices enable end‑to‑end completion in under 15 seconds, preserving responsiveness in real‑world conditions.
What user‑experience constraints guided the design of a voice workflow for non‑technical field‑service technicians?
The main UX constraint was simplicity. Field technicians work under time pressure and do not experiment with AI. The voice workflow needed to be discoverable, intuitive, and require minimal explanation, while avoiding chat‑style interfaces.
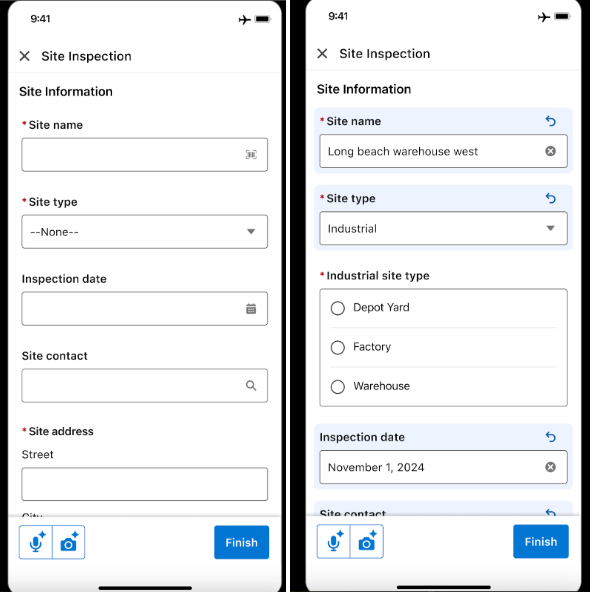
- Voice input embeds directly into existing form experiences.
- Technicians start voice capture with a single control and speak naturally without referencing field names.
- After processing, updated fields are visually highlighted.
- Inline undo and text‑editing controls keep users in full control—critical when AI modifies structured records.
Privacy considerations also shaped UX decisions. No voice recordings are stored; audio is discarded immediately after transcription. Extensive beta testing with enterprise customers confirmed that technicians prefer transparency and correction over silent automation, resulting in a voice experience that feels native to the workflow.
What cost‑to‑serve and privacy constraints influenced the decision to perform speech‑to‑text on the device?
- Cost – Cloud‑based transcription would create recurring expenses.
- Privacy – Sending audio to the cloud increases exposure of sensitive data.
By performing speech‑to‑text on the device using native OS frameworks, the team eliminated transcription costs and ensured audio never leaves the device. Once transcription finishes, the audio is immediately discarded; only the resulting text proceeds further. This simplifies compliance by avoiding storage, retention, and audit requirements for raw audio.
Text‑to‑form processing leverages existing cloud LLM infrastructure, minimizing incremental platform cost while retaining flexibility. Processed data is retained only as needed to populate the form, ensuring AI is applied where it adds semantic value. The remainder of the pipeline stays deterministic, cost‑efficient, and privacy‑safe.
Learn more
- Stay connected — join our Talent Community!
- Check out our Technology and Product teams to learn how you can get involved.