Building a Microservices Ecosystem: Stock Brokerage Simulator (My Broker B3)
Source: Dev.to
Hello, everyone!
I’m starting a series of articles to document the development of My Broker B3. This personal project applies advanced software engineering concepts, distributed systems, and messaging to simulate the real‑world operations of a stock brokerage. The main objective is to create an ecosystem that handles challenges such as data consistency, low latency, and asynchronous communication, while integrating a simplified matching engine.
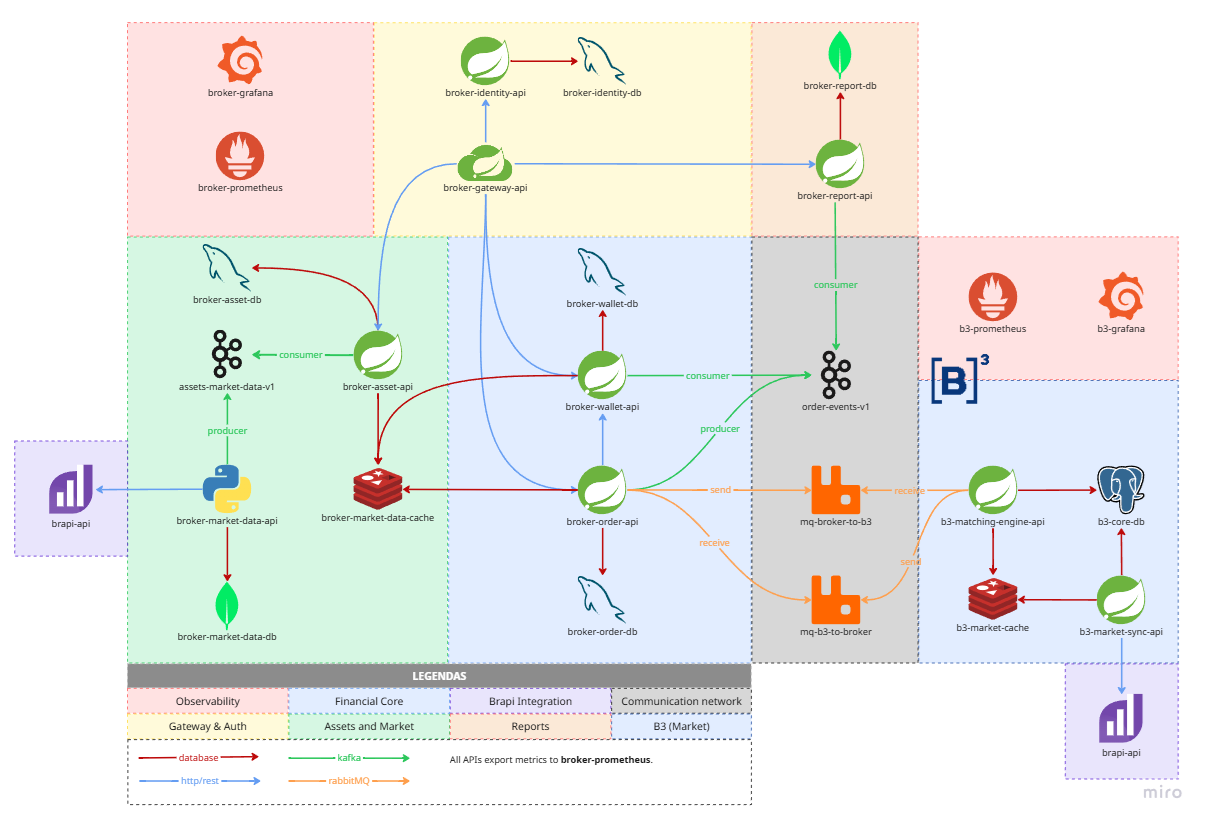
System Architecture
The project follows a microservices approach, using a hybrid stack to leverage the strengths of each ecosystem:
- Core Backend (Java/Spring Boot 3) – Provides the order (
broker-order-api), wallet (broker-wallet-api), and asset management (broker-asset-api) APIs. - Market Data (Python) – An integrator (
broker-market-data-api) that manages market‑data ingestion via scheduled tasks. - Matching Engine (Java) – A B3 simulator (
b3-matching-engine-api) that processes the execution of orders sent by the brokerage.
Data Flow and Technologies
A hybrid communication strategy ensures resilience and scalability.
Synchronous (REST)
Used for critical real‑time validations, such as verifying the wallet balance before allowing an order to be sent.
Asynchronous (Event‑Driven)
- Apache Kafka – Acts as an internal event bus for distributing market quotes and asset‑related events.
- RabbitMQ – Manages the communication between the Broker and the B3 Simulator through dedicated queues.
Persistence and Caching
Each service uses the data store that best fits its purpose.
| Technology | Use Case |
|---|---|
| MySQL / PostgreSQL | Transactional data, orders, and wallet history. |
| MongoDB | Market quotes history (time‑series data) within the Market Data API. |
| Redis | “Hot” cache for market prices to ensure ultra‑high‑speed queries. |
Technical Draw
What’s Next?
This post is just the kickoff. Upcoming articles will detail:
- Infrastructure – Deploying all resources on AWS (Free Tier).
- Messaging – Deep dive into Kafka and RabbitMQ configurations.
- Technical Challenges – Handling eventual consistency and the matching engine’s processing logic.
Feel free to leave your feedback or questions in the comments!