단일 데이터센터 탈피: k0smos 플랫폼을 활용한 실용적인 지리분산 AI 운영
출처: CNCF 블로그
2026년 6월 8일 게시
작성자: Prithvi Raj (Mirantis), Alexander Acker (Logsight.ai), Soeren Becker (Logsight.ai)
이 글에서 강조된 CNCF 프로젝트


단일 데이터센터 가정 깨기
현대 AI 아키텍처는 중앙 집중식이며 동질적인 데이터센터를 전제로 설계됩니다. 실제로는 인프라가 뒤죽박죽입니다. 대부분의 조직에서 컴퓨팅 자원은 프라이빗 클라우드, 연구 환경, 그리고 온프레미스와 엣지 하드웨어의 혼합 세대에 걸쳐 분산돼 있습니다. 운영 사일로에 갇힌 상태에서 이러한 분산 자원을 AI 워크로드에 활용하기란 매우 어렵습니다. GPU를 효율적으로 활용하는 것이 더 이상 단순히 계산 문제만이 아니라, 근본적인 인프라 문제입니다.
지리적으로 분산된 AI가 Kubernetes 문제인 이유
AI 인프라는 조용히 임계점을 넘어섰습니다. 모델을 더 빠르게 학습하고, 추론을 저렴하게 제공하며, 필요에 따라 컴퓨팅을 확장하려는 머신러닝 과제에서 시작했지만, 이제는 더 넓고 구조적인 문제로 변했습니다. OpenAI와 같은 기업이 Kubernetes 위에 기반을 구축하고, CNCF가 이 방향을 공식화하면서 Kubernetes는 AI 워크로드의 사실상 표준 오케스트레이션 레이어가 되었습니다. 지리적으로 분산된 AI는 이제 근본적으로 클라우드 네이티브 인프라 문제입니다.
하지만 워크로드가 단일 중앙 데이터센터를 벗어나 온프레미스 클러스터, 클라우드 리전, 엣지 배포까지 확장되면 복잡성은 기하급수적으로 증가합니다. 이제 단순히 학습 작업을 스케줄링하는 것이 아니라, 지리적 클러스터 수명주기를 관리하고, 사이트 간 연결성을 유지하며, NVLink와 같은 초고속 인터커넥트부터 HBM 같은 첨단 메모리 혁신까지 급변하는 하드웨어를 통합해야 합니다. 이러한 문제는 모두 Kubernetes 영역에 속하는 기본적인 분산 시스템 문제입니다.
이때 멀티클러스터 오케스트레이션은 선택이 아니라 필수가 됩니다. 단일 클러스터로는 이러한 지리적 범위를 커버할 수 없으며, 수동으로 관리되는 플릿은 팀을 금방 지치게 합니다. 필요한 것은 사이트 간 네트워킹과 이기종 하드웨어를 일관되게 처리하면서도 완전히 Kubernetes‑네이티브인 복원력 있는 플랫폼 레이어입니다. 결국 질문은 “AI를 Kubernetes에서 실행할 것인가?”가 아니라 “당신의 Kubernetes 플랫폼이 AI가 어디서든 실행될 수 있도록 설계되었는가?”가 됩니다.
k0smos 스택을 기반으로 사용하기
오픈소스 프로젝트들의 유기적인 집합인 k0smos 스택은 세 가지 기술 레이어에 책임을 분산시켜 지리적으로 분산된 AI 인프라를 운영하기 위한 아키텍처 기반을 제공합니다. 핵심은 k0s이며, 이는 단일 바이너리(의존성 제로)로 패키징된 CNCF‑준수 Kubernetes 배포판입니다. 특정 CNI, 런타임, 패키지 매니저에 대한 가정이 없기 때문에 k0s는 거의 모든 Linux 환경에서 호스트 OS를 오염시키지 않고 네이티브하게 실행됩니다. 이 경량 실행 모델은 파편화된 엣지 노드, 베어메탈 서버, 리소스가 제한된 VM에서도 표준 Kubernetes 워크로드를 구동할 수 있는 다목적 런타임이 됩니다.
이러한 배포를 대규모로 관리하기 위해 k0smotron이 호스티드 컨트롤 플레인(HCP) 엔진으로 동작합니다. k0smotron은 중앙 관리 클러스터 안에 격리된 버전 관리된 파드 형태로 k0s 컨트롤 플레인을 배포하는 Kubernetes 오퍼레이터이며, 컨트롤 플레인을 워커 노드와 완전히 분리합니다. 컨트롤 플레인을 동적으로 스케줄되는 워크로드로 취급함으로써 리소스 오버헤드를 크게 줄이고, 클라우드 인스턴스, 온프레미스 하드웨어, 엣지 노드 등 어느 지리적 환경에 있든 워커 노드를 중앙 관리 클러스터에 연결할 수 있는 원격 머신 모델을 구현합니다.
시스템을 묶어주는 k0rdent는 멀티클러스터 수명주기 오케스트레이션을 위한 선언형 관리 플레인입니다. 클러스터 플릿의 프로비저닝, 구성, 템플릿화를 Kubernetes‑네이티브 API로 추상화하여, 클러스터를 인프라‑코드로 선언·버전 관리·감사하는 GitOps 기반 워크플로우를 구축합니다. 멀티프로바이더 지원을 통해 k0rdent는 베어메탈, OpenStack, AWS, vSphere 등 어떤 컴퓨트 리소스 제공자를 사용하든 일관된 운영 인터페이스를 제공함으로써 플랫폼 레이어에서 이기종 하드웨어 환경을 사실상 표준화합니다.
지리적으로 분산된 이기종 AI 인프라 위에 구축된 현장 연구
위에서 소개한 k0smos 스택을 기반으로 독일 연방 혁신 파괴 기관(SPRIND)과 협업하고 있습니다. 공동 exalsius 프로젝트의 목표는 파편화된 이기종 GPU 하드웨어 자원을 하나의 통합 컴퓨트 시스템으로 묶는 것입니다.
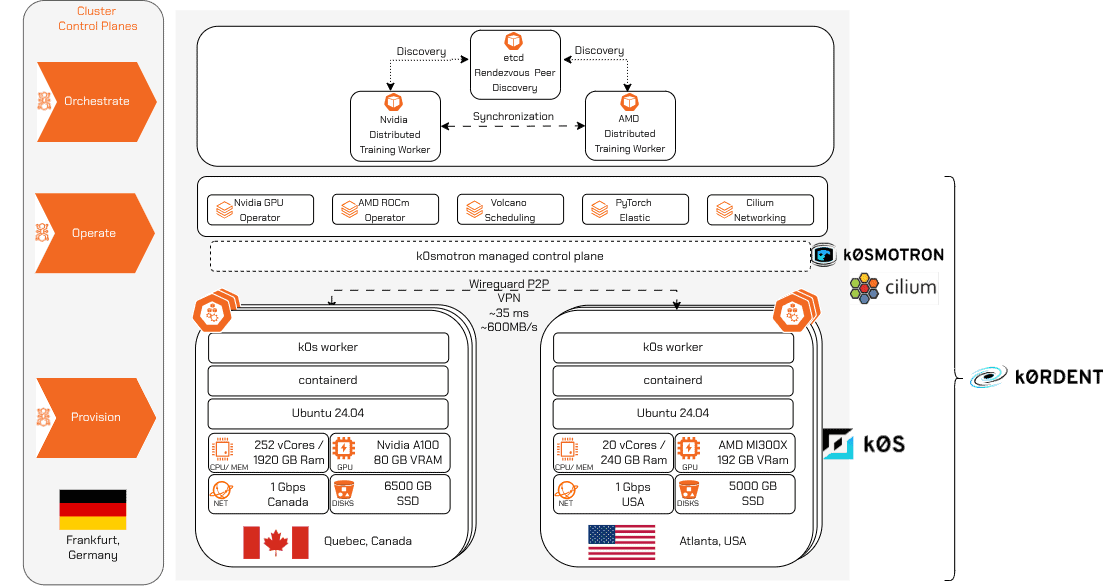
이 접근 방식을 검증하기 위해 오늘날 AI 인프라의 파편화된 현실을 반영한 환경을 구축했습니다. 아키텍처 다이어그램에 표시된 바와 같이, 퀘벡의 Nvidia A100 노드와 애틀랜타의 AMD MI300X 노드를 연결하는 환경을 만들었습니다. 클러스터 컨트롤 플레인은 독일 프랑크푸르트의 CPU 전용 노드에 호스팅됩니다. 이 설정은 국경·벤더를 초월한 GPU 환경이 하나의 시스템처럼 동작할 수 있음을 증명하고자 합니다.
k0smos 스택이 기본 클러스터 수명주기를 담당했기 때문에 별도의 맞춤형 관리 인프라를 구축할 필요가 없었습니다. 대신 하드웨어를 자동으로 탐지·프로파일링하는 컴포넌트를 추가하고(효율적인 학습 설정에 필수), 엔지니어링을 다음 세 가지 핵심 레이어에 집중했습니다:
-
프로비저닝: k0smotron ClusterAPI 프로바이더를 이용해 프랑크푸르트 관리 클러스터에서 직접 배포를 트리거했습니다. 퀘벡과 애틀랜타의 워커는 k0s와 각각의 벤더‑특화 GPU 소프트웨어 스택(Nvidia GPU Operator for A100, ROCm Operator for MI300X)으로 프로비저닝되었습니다.
-
운영: 사이트 간 연결성을 위해 CNCF 프로젝트 Cilium을 CNI로 배포하고, 워커 노드 간에 안전하고 직접적인 Wireguard P2P 터널(~35 ms 지연, ~600 MB/s)을 구축했습니다. 데이터 플레인 트래픽은 중앙 VPN 게이트웨이를 완전히 우회하고, 클러스터 상태는 프랑크푸르트에서 중앙 관리됩니다. 이 네트워크 위에 PyTorch Elastic, Ray, vLLM 등 AI 프레임워크를 k0rdent ServiceTemplates와 Helm 차트로 통합했으며, k0rdent 상태 관리자(KSM)와 Sveltos를 통해 프로비저닝했습니다.
-
오케스트레이션: P2P 네트워크 상에서 분산 학습 및 배치 워크로드를 안정적으로 실행하기 위한 운영 추상화와 비즈니스 로직을 추가했습니다.
첫 번째 현장 연구에서는 정적이고 지리적으로 분산된 환경에서 안정적이고 재현 가능한 AI 워크로드를 실행함으로써 이 아키텍처를 검증했습니다. GPT‑NeoX(LLM), ResNet(컴퓨터 비전), GCN(그래프 학습), PPO(강화 학습), Wav2Vec2(오디오) 등 다양한 레퍼런스 모델을 AMD와 Nvidia 노드에서 직접 학습시켰습니다.
성공의 핵심은 인프라와 학습 방법론을 공동 설계한 것이었습니다. 장거리 P2P 링크가 병목이 되지 않도록, 우리는 분산 저통신 학습 방식을 구현했으며, 이는 디커플드 모멘텀 최적화(자세한 내용은 NeurIPS 논문 [add-links] 및 코드 레포지토리 [add-link] 참고)를 활용했습니다. 하부 시스템 레이어가 이기종 하드웨어 실행을 담당하는 동안, 이 특화된 학습 레이어는 사이트 간 통신 부담을 크게 줄였습니다.
이 연구는 물리적 거리와 하드웨어 이기종성이 AI 워크로드의 실행 가능성을 제한하지 않음을 입증했습니다.